Partial Unique Index (조건부 유니크 인덱스)
학습 배경
방탈출 예약 대기 미션을 수행하면서, Reservation 테이블에 Status 필드를 생성하면서 Waiting 속성을 갖는 레코드가 여러 개 들어오는 것이 허용되면서(예를 들어, 특정 슬롯에 대해 예약 대기가 여러 개 생길 수 있다.) 유니크 제약 조건에 Status를 추가할 수 없었다.
ADD CONSTRAINT unique_reservation
UNIQUE (slot_id, user_id);
즉, 예약 대기(Waiting)가 들어오면서, 한 예약 슬롯에 동일한 Status가 여러 개 생기는 것을 허용해줘야 했고, *"같은 슬롯에는 RESERVED가 하나만 존재할 수 있음"*라는 불변식을 DB테이블 제약으로 막을 수 없게 되어버렸다.
하지만, 이런 조건을 만족하는 행만 인덱스를 걸어, 유니크 제약조건을 처리할 수 있는 기능을 Postgresql에서는 제공한다.
CREATE UNIQUE INDEX unique_reserved_slot
ON reservation (date, time_id, theme_id, store_id)
WHERE status = 'RESERVED';
다음과 같이 Where절을 사용하여 특정 조건(status = 'RESERVED'를 만족하는)을 만족하는 레코드에만 인덱스를 걸어 여기에 유니크 키를 걸어 줄 수 있다.
Partial Unique Index가 무엇인지 자세히 알아보자.
1. 언제 사용할까?
Partial Unique Index가 무엇인지 알아보기 이전에, 일반적인 제약조건을 추가할 때 발생할 수 있는 문제를 살펴보자.
대표적인 예시로 Soft Delete를 들 수 있다. 회원 탈퇴의 상황을 가정하자. 일반적인 서비스는 사용자가 회원탈퇴를 하더라도, 복구기능이나, 감사로그, 법적보관 등의 복잡한 이유로 Soft Delete 전략을 사용한다.
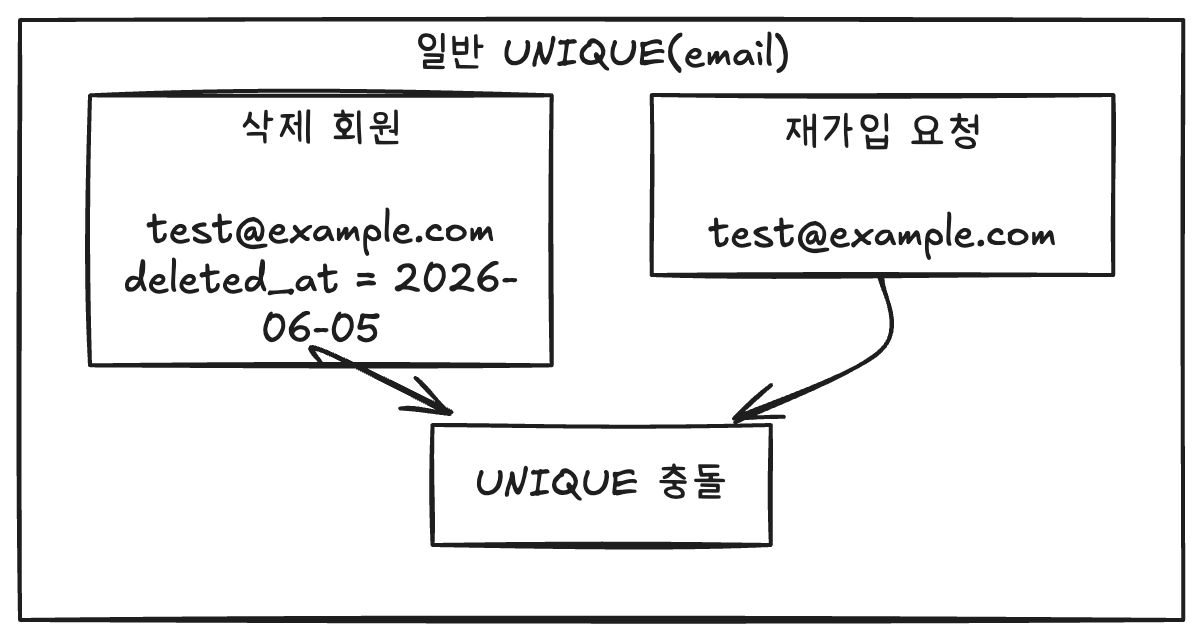
이때, 사용자 email에 Unique 제약조건이 걸려있다면, 해당 사용자가 다시 회원가입하는 경우 탈퇴를 했음에도 불가하고 레코드가 남아있어, 데이터베이스 제약 조건 위반으로 DuplicateKeyException이 발생하게 된다.
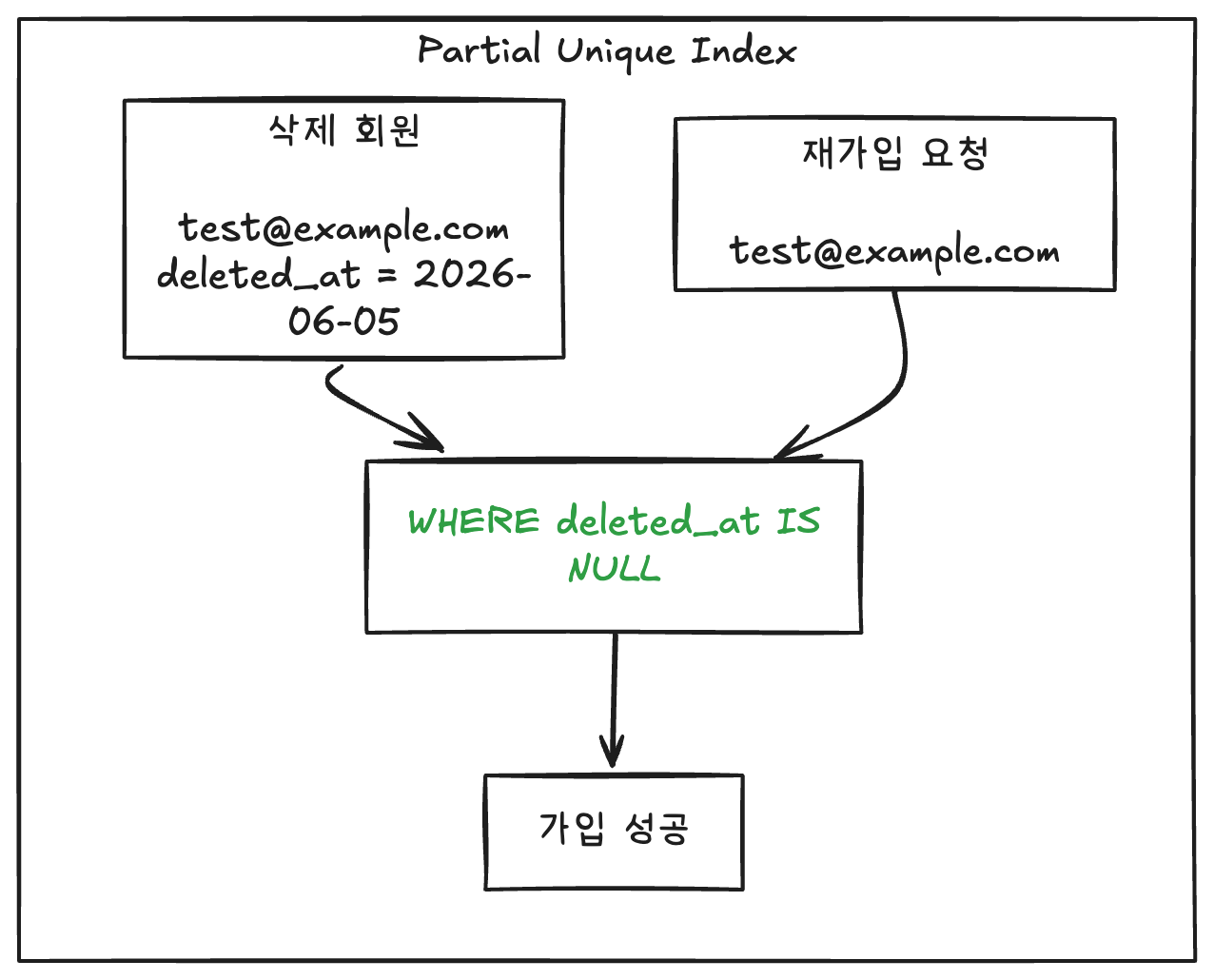
즉, 삭제된 회원의 Email은 유니크 제약 조건에서 무시되어야 한다. 이렇게 특정 상태값만 유니크가 보장되야 한다면 Partial Unique Index를 사용하여 아래와 같이 해결할 수 있다.
2. Partial Index를 먼저 알아보기
Partial Unique Index의 상위개념인 Partial Index(조건부 인덱스)에 대해 알아보자. 조건부 인덱스는 Postgresql이 제공하는 기능으로, 조건에 맞는 데이터만 인덱싱하는 인덱스를 의미한다.
CREATE INDEX idx_active_users
ON users(email)
WHERE deleted_at IS NULL;
이와 같이, deleted_at인 레코드에 대해서만 인덱스를 걸 수 있는 기능이다.
공식문서 번역: 부분 인덱스 (Partial Indexes)
3. Partial Unique Index란?
Partial Unique Index는 앞서 살펴본 Partial Index(조건부 인덱스)의 하위 개념이며, 이 인덱스에 유니크 키를 건 것을 의미한다.
CREATE UNIQUE INDEX idx_active_users
ON users(email)
WHERE deleted_at IS NULL;
(해당 쿼리문만 보아도 UNIQUE 키워드만 추가된 것을 확인 할 수 있다.)
4. Partial Unique Index를 사용하는 일반적인 케이스
일반적으로 앞서 살펴본 대로 조건에 만족하는 것에만 인덱스할 때 사용한다. 그리고 그 조건이 유니크해야 하는 경우에 조건부 유니크 인덱스를 사용한다.
4-1. 특정 상태 값만 유니크가 보장되어야 하는 경우
앞서 살펴본, soft-delete 사용시 deleted_at != null인 이메일은 유니크 조건에 포함시키지 않아야 한다거나(WHERE deleted_at IS NULL), RESERVATED인 예약은 하나만 있어야 하는 경우를 예시로 들 수 있다.
또 다른 예시로, 한 회원이 여러 개의 토글 버튼을 생성할 수 있지만, 활성화된 토글(is_active = true)은 단 하나만 존재해야 할 때도 Partial Unique Index를 고려할 수 있다.
4-2. Null을 명시적으로 처리해야 하는 경우
데이터베이스마다 Unique 제약을 걸 때 특히 Null은 처리방식이 달라, Null 중복처리가 모호해질 수 있다.
예를 들어, 특정 사용자의 주소 필드가 Nullable이라고 가정하자.
CREATE TABLE users (
address VARCHAR(255) UNIQUE
);
이때, 아래와 같이 Null로 Insert를 수행하는 경우, Unique 제약 조건에 걸릴 것이라고 생각하지만 문제없이 허용된다.
INSERT INTO users(address) VALUES (NULL);
INSERT INTO users(address) VALUES (NULL);
INSERT INTO users(address) VALUES (NULL);
-- 문제 없이 허용
이는, SQL표준에서 NULL을 값은 값으로 보지 않고, 서로 다른 값으로 취급하기 때문이다. (Null != Null)이다.
따라서, WHERE address IS NOT NULL 조건으로 인덱스를 생성하면 값이 있는 데이터에만 유니크 제약이 깔끔하게 적용할 수 있다.
(첨언: PostgreSQL 15부터는 인덱스 옵션에 NULLS NOT DISTINCT라는 기능이 추가되어 NULL도 같은 값으로 취급할 수 있도록 설정할 수 있다.)
weggle-plus의 조회수가 실제보다 8배 부풀려졌다 — 블로그 중복 방지 시스템 설계와 구현기 블로그 포스트에서도 Null을 조건부 유니크 제약으로 걸어서, 비회원 조회랑 회원 조회 중복 저장 정합성을 해결한 사례를 엿볼 수 있다.
5. 성능적 이점
인덱스 범위를 좁혀줄 수 있다는 측면에서 조건부 인덱스는 성능적으로 유리할 수 있다. 예를 들어, "포스트 조회 기록" 테이블에서 user_id와 post_id를 유니크 제약 조건으로 인덱싱한다고 했을 때, 일반적인 인덱스라면 모든 모든 행이 다 인덱스 될 것이다. 하지만 Partial Unique Index로 user_id != Null을 걸어줬다면, user_id가 있는 행만 인덱스가 걸리게 되어 범위가 줄어든다.
6. 지원하는 데이터베이스
이 Partial Unique Index를 모든 데이터베이스에서 제공하지는 않는다. 우선 표로 지원 현황을 정리해보았다.
| DBMS | Partial Index | Partial Unique Index | 구현 방식 | 비고 |
|---|---|---|---|---|
| PostgreSQL | ⭕️ | ⭕️ | WHERE 절 |
Partial Index의 사실상 표준 구현체 |
| SQLite | ⭕️ | ⭕️ | WHERE 절 |
PostgreSQL과 거의 동일한 문법 지원 |
| SQL Server (MSSQL) | ⭕️ | ⭕️ | Filtered Index (WHERE) |
이름만 다를 뿐 개념은 동일 |
| MongoDB | 유사 개념 제공 | 유사 개념 제공 | partialFilterExpression |
문서(Document) 기반 조건부 Unique 지원 |
| MySQL (InnoDB) | ❌ | ❌ | Generated Column + Unique Index | 공식 Partial Index 미지원 |
| MariaDB | ❌ | ❌ | Generated Column 활용 우회 | MySQL과 유사 |
| Oracle | ❌ | ❌ | Function-Based Index 활용 | Partial Index 개념 직접 지원 안 함 |
PostgreSQL과 SQLite는 앞서 살펴본 방식대로 가장 표준적인 WHERE 절 문법을 사용하여 인덱스를 생성한다. SQL Server (MSSQL)도 이름만 다를 뿐이지, WHERE 조건을 활용해 Filtered Index 형식으로 고유 인덱스를 만든다.
MongoDB는 partialFilterExpression 옵션을 활용하여 특정 조건을 충족하는 도큐먼트에만 유니크 제약을 적용할 수 있다. deletedAt = null 인 문서에 대해서만 email 유니크 제약 적용하고 싶다면, 다음과 같이 작성할 수 있다.
db.users.createIndex(
{ email: 1 },
{
unique: true,
partialFilterExpression: {
deletedAt: null
}
}
)
MySQL(InnoDB)를 주의해야 한다. MySQL은 표준 문법으로서의 Partial Index를 지원하지 않는다. 대신 가상 컬럼(Generated Column)을 생성하고 해당 가상 컬럼에 유니크 인덱스를 거는 방식으로 우회하여 이 기능을 구현할 수 있다.
ALTER TABLE users
ADD active_email VARCHAR(255)
GENERATED ALWAYS AS (
CASE
WHEN deleted_at IS NULL
THEN email
ELSE NULL
END
);
CREATE UNIQUE INDEX uq_active_email
ON users(active_email);
7. 주의할 점
주의할 점1. MySQL에도 Partial Index가 있던데?
MySQL의 Partial Index라고 불리는 것은 Postgresql의 Partial Index와 전혀 다른 개념이다. Postgresql의 Partial Index는 인덱스 자체에 WHERE 조건을 거는 것이라면, MySQL의 Partial Index는 특정 컬럼의 일부분만 인덱싱하는 것을 의미한다. (예를 들어, 특정 사용자 이름의 앞글자 10자리만 인덱싱하는 것)
주의할 점2. 조회 쿼리를 사용할 때 Planner가 인식할 수 있도록 설정해야 한다.
Partial Index는 조건을 만족하는 일부 데이터만 들어있는 인덱스이기 때문에, 데이터베이스의 Query Planner가 조회 시점에 그 조건을 만족한다고 확신할 수 있을 때만 인덱스를 사용하여 조회를 처리한다.
아래 예시를 통해 자세히 살펴보자.
id | email | deleted_at
1 | a@test.com | NULL
2 | a@test.com | 2026-06-05
DB에 다음과 같이 레코드가 저장되어 있으며, 조건부 유니크 인덱스인 uq_active_user_email (deleted_at IS NULL)가 걸려있다고 가정하자.
SELECT *
FROM users
WHERE email = 'a@test.com';
이때 다음과 같은 SELECT 쿼리가 들어온다면, uq_active_user_email를 통해서는 1번 데이터밖에 찾지 못하기 때문에, Query Planner는 uq_active_user_email를 사용하지 않고 조회를 처리한다.
즉, 인덱스 조건이 WHERE deleted_at IS NULL 이라면, 조회 쿼리에도 deleted_at IS NULL 조건이 명시되어 있어야
uq_active_user_email인덱스 사용하여 조회를 처리한다.
즉, 명시적으로 조건부 유니크 인덱스와 쿼리의 조건절이 일치하는 경우에만 해당 인덱스를 활용하여 조회 쿼리를 처리한다는 것을 유의해야 한다.
여기서 주의할 점: 유니크 제약 검사와 여기서 살펴본 조회시 인덱스의 역할을 분리해서 생각해야 한다. uq_active_user_email는 INSERT와 UPDATE시점에는 DB가 자동으로 유니크 검사를 하여 불변식을 맞춰주기 때문에 이 점을 고려할 필요가 없지만, 조회 성능을 최적화하기 위한 용도로(즉, 인덱스로) 사용될 때는 쿼리 WHERE 조건이 맞아야 한다는 것을 고려해야 한다.
주의할 점3. WHERE 절의 조건에 값이 변하는 함수는 사용할 수 없다.
Partial Unique Index의 WHERE 절 조건에 NOW()나 RAND() 같이 호출할 때마다 값이 변하는 함수(Mutable Function)는 사용할 수 없다.
예를 들어, 최근 7일 이내 회원가입한 사용자만 인덱스를 걸고 싶다고 가정하자.
WHERE created_at > NOW() - INTERVAL '7 days'
여기는 NOW()는 함수의 호출시점에 따라 값이 달라지는 Mutable 함수이다. 그렇기 때문에 이 조건절을 사용해서 인덱스를 생성한 다음날이 되면 인덱스의 내용과 실제 조건이 달라지는 문제가 발생한다.
따라서 PostgreSQL는 값이 변하는 함수를 Partial Index 조건에서 금지하고 있다.
ERROR:
functions in index predicate must be marked IMMUTABLE
주의할점4. Partial Unique Index 사용 시 UPSERT 작성 시 주의사항
우선 여기서 UPSERT는 PostgreSQL의 문법으로 없으면 INSERT, 있으면 UPDATE혹은 무시를 하는 기능을 의미한다. 아래와 같이 INSERT와 ON CONFLICT 조합으로 구현할 수 있는데, 이때 주의할 점을 살펴보자.
일반 UNIQUE Index는 ON CONFLICT(column) 만으로도 PostgreSQL이 충돌 대상을 찾을 수 있다. 다음과 같이 일반 유니크 인덱스가 걸린 경우
CREATE UNIQUE INDEX uq_email
ON users(email);
다음과 같이 UPSERT를 진행해도 uq_email 충돌 조건으로 인지하고 전혀 문제가 발생하지 않는다.
INSERT INTO users(email)
VALUES ('test@test.com')
ON CONFLICT (email)
DO NOTHING;
하지만 Partial Unique Index는 특정 조건을 만족하는 행에만 UNIQUE 제약이 적용되기 때문에, 이 조건또한 충돌 조건에 명시해줘야 한다. 아래와 같은 Partial Unique Index이 있다고 가정하자.
CREATE UNIQUE INDEX uq_active_email
ON users(email)
WHERE deleted_at IS NULL;
이 unique 인덱스는 활성 사용자끼리만 email이 중복 금지라는 불변식을 표현한다. 위의 UPSERT문이 실행된다면, PostgreSQL 입장에서는 uq_active_email는 모든 행에 적용되는 것이 아니라고 해석하고 있기 때문에 ON CONFLICT (email)가 들어오는 경우에 "활성 사용자 충돌인지, 삭제 사용자 포함 충돌인지" 판단할 수 없게 되고, 결국 어떤 인덱스를 사용해야 하는지 확신할 수 없다.
따라서 아래 쿼리와 같이, ON CONFLICT 사용 시 PostgreSQL이 어떤 Partial Unique Index를 기준으로 충돌을 검사해야 하는지 알 수 있도록 인덱스의 WHERE 조건을 함께 명시해야 한다.
INSERT INTO users(email, deleted_at)
VALUES ('test@test.com', NULL)
ON CONFLICT (email)
WHERE deleted_at IS NULL
DO NOTHING;